-
![[image]](/cache/files.balancer.ru/forums/attaches/2014/12/128x128-crop/11-3672861-q4.png)
Производительность SQL
Теги:
 digger
digger
Запрос примерно такой
select ID from table1 where size < 10000 and ID not in (select ID from table2)
Обе таблицы большие,около 10 миллионов.Очень тормозит.Что мне надо логически? Пройтись по table1 и выбрать набор ID,затем для каждого ID проверить,что он не в table2,где он является также индексом.Тормозить вроде нечему.В чем причина тормозов и можно ли ускорить? Я подозреваю,что select ID from table2 формирует временный рекордсет огромного размера вместо того,чтобы просто смотреть в таблицу.
select ID from table1 where size < 10000 and ID not in (select ID from table2)
Обе таблицы большие,около 10 миллионов.Очень тормозит.Что мне надо логически? Пройтись по table1 и выбрать набор ID,затем для каждого ID проверить,что он не в table2,где он является также индексом.Тормозить вроде нечему.В чем причина тормозов и можно ли ускорить? Я подозреваю,что select ID from table2 формирует временный рекордсет огромного размера вместо того,чтобы просто смотреть в таблицу.

 инфо
инфо инструменты
инструменты Luchnik
Luchnik

А если так :
select ID from table1 t1 where t1.size < 10000
and not exists (select t2.ID from table2 t2 where t2.ID = t1.ID)
?
Или
select distinct t1.ID from table1 t1
left join table2 t2 on t2.ID = t1.ID
where t1.size < 10000 and t2.ID is null
select ID from table1 t1 where t1.size < 10000
and not exists (select t2.ID from table2 t2 where t2.ID = t1.ID)
?
Или
select distinct t1.ID from table1 t1
left join table2 t2 on t2.ID = t1.ID
where t1.size < 10000 and t2.ID is null


Distinct - зло.
Особенно на больших таблицах - тормоза с tempdb гарантированы.
Особенно на больших таблицах - тормоза с tempdb гарантированы.


yacc> Distinct - зло.
yacc> Особенно на больших таблицах - тормоза с tempdb гарантированы.
Не зло, конечно, если использовать его тогда, когда требуется. А в этом случае он вообще не в кассу - ID, скорее всего, является первичным ключом и его уникальность гарантирована.
yacc> Особенно на больших таблицах - тормоза с tempdb гарантированы.
Не зло, конечно, если использовать его тогда, когда требуется. А в этом случае он вообще не в кассу - ID, скорее всего, является первичным ключом и его уникальность гарантирована.

yacc> Distinct - зло.
yacc> Особенно на больших таблицах - тормоза с tempdb гарантированы.
Я согласен.
Но если у него всё упирается в память, то может оказаться лучше оригинального варианта.
Кроме того, возможно, что по логике построения таблиц Distinct и не нужен. Если 1 к 1-му.
yacc> Особенно на больших таблицах - тормоза с tempdb гарантированы.
Я согласен.
Но если у него всё упирается в память, то может оказаться лучше оригинального варианта.
Кроме того, возможно, что по логике построения таблиц Distinct и не нужен. Если 1 к 1-му.
Akuma> Не зло, конечно
С точки зрения плана - зло.
Просто когда не критично можно использовать.
С точки зрения плана - зло.
Просто когда не критично можно использовать.
Akuma> Не зло, конечно, если использовать его тогда, когда требуется. А в этом случае он вообще не в кассу - ID, скорее всего, является первичным ключом и его уникальность гарантирована.
Согласен, согласен. Но тут мы точно не знаем - см. мой ответ yacc.
Согласен, согласен. Но тут мы точно не знаем - см. мой ответ yacc.
Luchnik> Но если у него всё упирается в память, то может оказаться лучше оригинального варианта.
На МS-SQL это с гарантией tempdb независимо от памяти")
И скорость уже будет определятся скоростью винчестера
На МS-SQL это с гарантией tempdb независимо от памяти
И скорость уже будет определятся скоростью винчестера
Luchnik>> Но если у него всё упирается в память, то может оказаться лучше оригинального варианта.
yacc> На МS-SQL это с гарантией tempdb независимо от памяти
yacc> И скорость уже будет определятся скоростью винчестера
Я готов рассмотреть твой вариант.
yacc> На МS-SQL это с гарантией tempdb независимо от памяти
yacc> И скорость уже будет определятся скоростью винчестера
Я готов рассмотреть твой вариант.
Luchnik> Я готов рассмотреть твой вариант.
Детали надо.
Ключи и индексы.
Детали надо.
Ключи и индексы.
Luchnik> Кроме того, возможно, что по логике построения таблиц Distinct и не нужен. Если 1 к 1-му.
Даже если 1 ко многим - нам по условию задачи нужно выбрать t1.ID, для которых нет соответствия t2.ID.
Даже если 1 ко многим - нам по условию задачи нужно выбрать t1.ID, для которых нет соответствия t2.ID.
yacc> Детали надо.
yacc> Ключи и индексы.
Для начала нужно узнать, какой сервер БД.
yacc> Ключи и индексы.
Для начала нужно узнать, какой сервер БД.

Luchnik> select ID from table1 t1 where t1.size < 10000
Luchnik> and not exists (select t2.ID from table2 t2 where t2.ID = t1.ID)
Это первое, что стоит попробовать. Самое простое.
А вообще полезно знать корреляцию t1 и t2.
Если она низкая и есть индексы по id обеих таблиц, то:
select t.id
from
(select t1.ID from table1 t1
inner join table2 t2
on t2.ID = t1.ID) t inner join table1 tt on t.id = tt.id
where tt.size < 10000
Внутренний запрос здесь он сделает по merge join, т.к. оба входа у него отсортированы, на выходе будет немного записей, которые добьет по size. Это микрософак как я понимаю? На оракле я б внутри написал select t1.ROWID, а на MS SQL не помню, если индекс по id кластерный то смысла нет.
Luchnik> and not exists (select t2.ID from table2 t2 where t2.ID = t1.ID)
Это первое, что стоит попробовать. Самое простое.
А вообще полезно знать корреляцию t1 и t2.
Если она низкая и есть индексы по id обеих таблиц, то:
select t.id
from
(select t1.ID from table1 t1
inner join table2 t2
on t2.ID = t1.ID) t inner join table1 tt on t.id = tt.id
where tt.size < 10000
Внутренний запрос здесь он сделает по merge join, т.к. оба входа у него отсортированы, на выходе будет немного записей, которые добьет по size. Это микрософак как я понимаю? На оракле я б внутри написал select t1.ROWID, а на MS SQL не помню, если индекс по id кластерный то смысла нет.
16-й> Если она низкая и есть индексы по id обеих таблиц, то:
Там NOT IN стоит - в этом-то и прикол
Там NOT IN стоит - в этом-то и прикол
yacc> Там NOT IN стоит - в этом-то и прикол
Посыпаю чувствительные места, и точно, cтоит
Значит захинтовать его, гада, каким-нибудь hash anti-join, чтоб он за каждой записью не бегал в подзапрос.
Посыпаю чувствительные места, и точно, cтоит
Значит захинтовать его, гада, каким-нибудь hash anti-join, чтоб он за каждой записью не бегал в подзапрос.
Это сообщение редактировалось 11.12.2014 в 17:19

digger> select ID from table1 where size < 10000 and ID not in (select ID from table2)
MySQL очень плохо работает с вложенными запросами такого вида. По крайней мере раньше плохо работал. Нужно пользоваться JOIN'ами, типа такого:
Ну и, понятно, должны быть индексы по ID, по size, а для table1, может, и составной ID, size.
MySQL очень плохо работает с вложенными запросами такого вида. По крайней мере раньше плохо работал. Нужно пользоваться JOIN'ами, типа такого:
code mysql
Ну и, понятно, должны быть индексы по ID, по size, а для table1, может, и составной ID, size.

Кстати, вложенные SELECT'ы в MySQL работают (опять же, раньше так было, говорят, что в 5.6 и старше много оптимизировали на этот счёт, но я пока не проверял) настолько отвратительно, что при сложных случаях выгодно сделать временную таблицу из результата [бывшего вложенного] запроса, добавить к ней нужные индексы и уже её джойнить к нашему запросу вместо вложенного. Разница в производительности получается на порядки.
16-й> Значит захинтовать его, гада, каким-нибудь hash anti-join, чтоб он за каждой записью не бегал в подзапрос.
На MS-SQL с хинтами плоховато
там бы я использовал времянку, что-то типа такого
CREATE TABLE #t ( ID int, CONSTRAINT [#IQ] UNIQUE ( ID ) )
INSERT #t
SELECT ID FROM table1 WHERE size < 10000
DELETE t1
FROM #t t1
INNER JOIN table2 t2 ON t1.ID = t2.ID
после этого в #t - искомый набор ID
На MS-SQL с хинтами плоховато
там бы я использовал времянку, что-то типа такого
CREATE TABLE #t ( ID int, CONSTRAINT [#IQ] UNIQUE ( ID ) )
INSERT #t
SELECT ID FROM table1 WHERE size < 10000
DELETE t1
FROM #t t1
INNER JOIN table2 t2 ON t1.ID = t2.ID
после этого в #t - искомый набор ID
yacc> На MS-SQL с хинтами плоховато
yacc> там бы я использовал времянку, что-то типа такого
yacc> CREATE TABLE #t ( ID int, CONSTRAINT [#IQ] UNIQUE ( ID ) )
yacc> INSERT #t
yacc> SELECT ID FROM table1 WHERE size < 10000
yacc> DELETE t1
yacc> FROM #t t1
yacc> INNER JOIN table2 t2 ON t1.ID = t2.ID
yacc> после этого в #t - искомый набор ID
Не, ну я настаиваю! Это ж природная редкость, когда два входа с покрывающими индексами под merge.
select t.id
from
(select t1.ID, t2.ID AS id_table2 from table1 t1
left join table2 t2
on t2.ID = t1.ID) t inner join table1 tt on t.id = tt.id
where t.id_table2 IS NULL AND tt.size < 10000
yacc> там бы я использовал времянку, что-то типа такого
yacc> CREATE TABLE #t ( ID int, CONSTRAINT [#IQ] UNIQUE ( ID ) )
yacc> INSERT #t
yacc> SELECT ID FROM table1 WHERE size < 10000
yacc> DELETE t1
yacc> FROM #t t1
yacc> INNER JOIN table2 t2 ON t1.ID = t2.ID
yacc> после этого в #t - искомый набор ID
Не, ну я настаиваю! Это ж природная редкость, когда два входа с покрывающими индексами под merge.
select t.id
from
(select t1.ID, t2.ID AS id_table2 from table1 t1
left join table2 t2
on t2.ID = t1.ID) t inner join table1 tt on t.id = tt.id
where t.id_table2 IS NULL AND tt.size < 10000
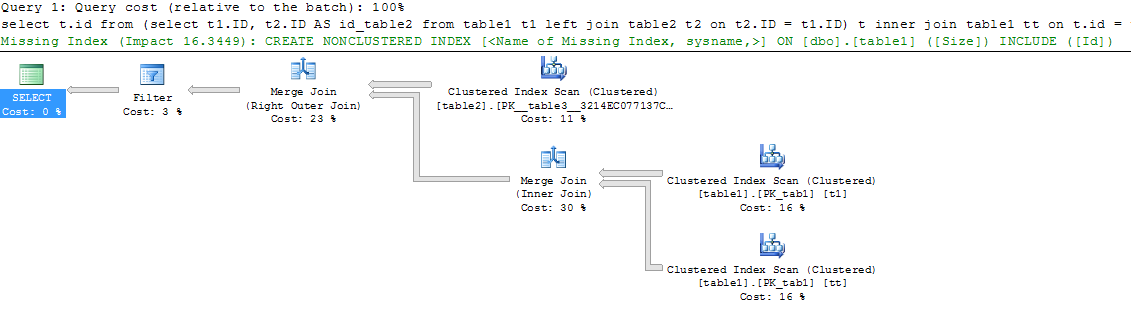
16-й> Не, ну я настаиваю!
А я просто покажу - раз
select *
from table1 t1
where t1.size > 3
and t1.Id not in ( select Id from table2 )
/*
(14682 row(s) affected)
Table 'table1'. Scan count 1, logical reads 164, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'table2'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
*/
А я просто покажу - раз
select *
from table1 t1
where t1.size > 3
and t1.Id not in ( select Id from table2 )
/*
(14682 row(s) affected)
Table 'table1'. Scan count 1, logical reads 164, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'table2'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
*/
Прикреплённые файлы:

то, что предлагал 16-й - два -
select t.id
from
(select t1.ID, t2.ID AS id_table2 from table1 t1
left join table2 t2
on t2.ID = t1.ID) t inner join table1 tt on t.id = tt.id
where t.id_table2 IS NULL AND tt.size > 3
/*
(14682 row(s) affected)
Table 'table1'. Scan count 2, logical reads 328, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'table2'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
*/
select t.id
from
(select t1.ID, t2.ID AS id_table2 from table1 t1
left join table2 t2
on t2.ID = t1.ID) t inner join table1 tt on t.id = tt.id
where t.id_table2 IS NULL AND tt.size > 3
/*
(14682 row(s) affected)
Table 'table1'. Scan count 2, logical reads 328, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'table2'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
*/
Прикреплённые файлы:
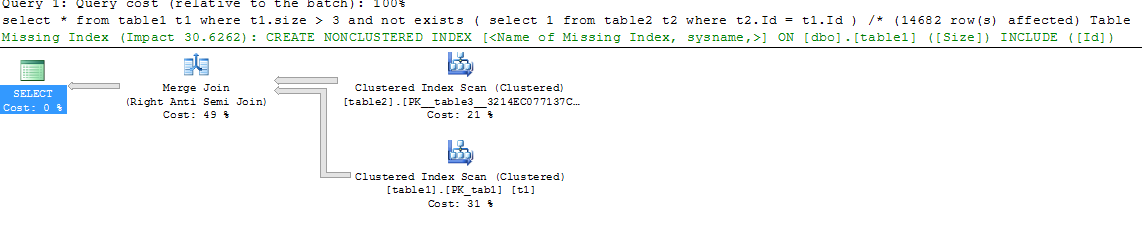
три
select *
from table1 t1
where t1.size > 3
and not exists ( select 1 from table2 t2 where t2.Id = t1.Id )
/*
(14682 row(s) affected)
Table 'table1'. Scan count 1, logical reads 164, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'table2'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
*/
select *
from table1 t1
where t1.size > 3
and not exists ( select 1 from table2 t2 where t2.Id = t1.Id )
/*
(14682 row(s) affected)
Table 'table1'. Scan count 1, logical reads 164, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'table2'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
*/
Прикреплённые файлы:
С времянкой и апдейтом - четыре
CREATE TABLE #t ( ID int, CONSTRAINT t_Q UNIQUE ( ID ), exclude int default(0) )
INSERT #t ( Id )
SELECT ID FROM table1 WHERE size > 3
UPDATE t1
set exclude = 1
FROM #t t1
INNER JOIN table2 t2 ON t1.ID = t2.ID
SELECT * FROM #t WHERE exclude = 0
DROP TABLE #t
/*
Table '#t_______0000000000E6'. Scan count 0, logical reads 238547, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'table1'. Scan count 1, logical reads 164, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(79167 row(s) affected)
(1 row(s) affected)
Table '#t______0000000000E6'. Scan count 1, logical reads 64664, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'table2'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(64485 row(s) affected)
(1 row(s) affected)
(14682 row(s) affected)
Table '#t_____0000000000E6'. Scan count 1, logical reads 167, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
*/
CREATE TABLE #t ( ID int, CONSTRAINT t_Q UNIQUE ( ID ), exclude int default(0) )
INSERT #t ( Id )
SELECT ID FROM table1 WHERE size > 3
UPDATE t1
set exclude = 1
FROM #t t1
INNER JOIN table2 t2 ON t1.ID = t2.ID
SELECT * FROM #t WHERE exclude = 0
DROP TABLE #t
/*
Table '#t_______0000000000E6'. Scan count 0, logical reads 238547, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'table1'. Scan count 1, logical reads 164, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(79167 row(s) affected)
(1 row(s) affected)
Table '#t______0000000000E6'. Scan count 1, logical reads 64664, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'table2'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(64485 row(s) affected)
(1 row(s) affected)
(14682 row(s) affected)
Table '#t_____0000000000E6'. Scan count 1, logical reads 167, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
*/
Прикреплённые файлы:

Дополнение - таблицы не особо большие и только кластерный индекс на Id
Copyright © Balancer 1997..2024
Создано 11.12.2014
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
Создано 11.12.2014
Связь с владельцами и администрацией сайта: anonisimov@gmail.com, rwasp1957@yandex.ru и admin@balancer.ru.
